Rows: 22616 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): line, song_name, artist_name
dbl (3): song_id, artist_id, song_line
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 132 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (4): Artist, Album, Title, Lyrics
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Data pre-processing and feature engineering
It appears the beyonce_lyrics and the taylor_swift_lyrics are the pertinent data sets for building our machine learning classifier. Let’s have a closer look at the two datasets.
beyonce_lyrics
# A tibble: 22,616 × 6
line song_id song_name artist_id artist_name song_line
<chr> <dbl> <chr> <dbl> <chr> <dbl>
1 If I ain't got nothing, I … 50396 1+1 498 Beyoncé 1
2 If I ain't got something, … 50396 1+1 498 Beyoncé 2
3 'Cause I got it with you 50396 1+1 498 Beyoncé 3
4 I don't know much about al… 50396 1+1 498 Beyoncé 4
5 And it's me and you 50396 1+1 498 Beyoncé 5
6 That's all we'll have when… 50396 1+1 498 Beyoncé 6
7 'Cause baby, we ain't got … 50396 1+1 498 Beyoncé 7
8 Darling, you got enough fo… 50396 1+1 498 Beyoncé 8
9 So come on, baby, make lov… 50396 1+1 498 Beyoncé 9
10 When my days look low 50396 1+1 498 Beyoncé 10
# ℹ 22,606 more rows
# A tibble: 132 × 4
artist album title lyrics
<chr> <chr> <chr> <chr>
1 Taylor Swift Taylor Swift Tim McGraw "He said the way my blu…
2 Taylor Swift Taylor Swift Picture to Burn "State the obvious, I d…
3 Taylor Swift Taylor Swift Teardrops on my Guitar "Drew looks at me,\nI f…
4 Taylor Swift Taylor Swift A Place in This World "I don't know what I wa…
5 Taylor Swift Taylor Swift Cold As You "You have a way of comi…
6 Taylor Swift Taylor Swift The Outside "I didn't know what I w…
7 Taylor Swift Taylor Swift Tied Together With A Smile "Seems the only one who…
8 Taylor Swift Taylor Swift Stay Beautiful "Cory's eyes are like a…
9 Taylor Swift Taylor Swift Should’ve Said No "It's strange to think …
10 Taylor Swift Taylor Swift Mary’s Song "She said\n\"I was seve…
# ℹ 122 more rows
glimpse(taylor_swift_lyrics)
Rows: 132
Columns: 4
$ artist <chr> "Taylor Swift", "Taylor Swift", "Taylor Swift", "Taylor Swift",…
$ album <chr> "Taylor Swift", "Taylor Swift", "Taylor Swift", "Taylor Swift",…
$ title <chr> "Tim McGraw", "Picture to Burn", "Teardrops on my Guitar", "A P…
$ lyrics <chr> "He said the way my blue eyes shinx\nPut those Georgia stars to…
The beyonce_lyrics appears to be structured differently than the taylor_swift_lyrics. The lyrics from Taylor Swift is stored 1 line per title/song name, while Beyonce’s lyrics are stored by song lines. This is a problem, and we’ll have to rectify this prior to building our classifier.
My idea of rectifying this would be to collapse the data from Beyonce’s lyrics to get them into the same structure as Taylor Swift’s lyrics.
`summarise()` has grouped output by 'artist_name'. You can override using the
`.groups` argument.
beyonce_lyrics
# A tibble: 391 × 3
artist title lyrics
<chr> <chr> <chr>
1 Beyoncé "\"Self-Titled\" Part 1 . The Visual Album" "I see music. I…
2 Beyoncé "\"Self-Titled\" Part 2 . Imperfection" "There's a mome…
3 Beyoncé "***Flawless (Ft. Chimamanda Ngozi Adichie)" "Your challenge…
4 Beyoncé "***Flawless (Remix) (Ft. Nicki Minaj)" "Dum-da-de-da D…
5 Beyoncé "1+1" "If I ain't got…
6 Beyoncé "2017 Grammy's Best Urban Contemporary Album Speech" "Thank you so m…
7 Beyoncé "6 Inch (Ft. The Weeknd)" "Six inch heels…
8 Beyoncé "7/11" "Shoulders side…
9 Beyoncé "7/11 (Homecoming Live)" "Goddamn, godda…
10 Beyoncé "A Woman Like Me" "Do you think Y…
# ℹ 381 more rows
Okay - this appears to be much better, and will allow us to merge them together with the Taylor Swift data. Our outcome y that we are trying to predict will be the ‘artist’ column. The features x will be the song lyrics. In order to get them to a usable state for our model, we will have to perform some preprocessing and feature engineering.
# A tibble: 523 × 3
artist title lyrics
<chr> <chr> <chr>
1 Taylor Swift Tim McGraw "He said the way my blue eyes shinx\…
2 Taylor Swift Picture to Burn "State the obvious, I didn't get my …
3 Taylor Swift Teardrops on my Guitar "Drew looks at me,\nI fake a smile s…
4 Taylor Swift A Place in This World "I don't know what I want, so don't …
5 Taylor Swift Cold As You "You have a way of coming easily to …
6 Taylor Swift The Outside "I didn't know what I would find\nWh…
7 Taylor Swift Tied Together With A Smile "Seems the only one who doesn't see …
8 Taylor Swift Stay Beautiful "Cory's eyes are like a jungle\nHe s…
9 Taylor Swift Should’ve Said No "It's strange to think the songs we …
10 Taylor Swift Mary’s Song "She said\n\"I was seven, and you we…
# ℹ 513 more rows
After merging the data together, we will split our data into a separate training and testing dataset.
The data has now been split, where 75% of the data we have available will be used to train our classifier, and the remaining 25% will be left for validation of the model and to estimate the overall performance.
We will next create a ‘recipe’ and perform feature engineering on our training data. We will do this in various steps, including tokenizing the lyrics, removing stop words, excluding words that appear less than 20 times, performing term-frequency inverse-document-frequency (TF-IDF), and finally normalization.
• Term frequency-inverse document frequency with: lyrics
• Centering and scaling for: all_predictors()
Now that we have a ‘recipe’ for pre-processing our data into a usable state to feed into our model, we will create a specification of the classifier. In this instance we will be building a support vector machine (SVM) classifier from the kernlab package.
Radial Basis Function Support Vector Machine Model Specification (classification)
Main Arguments:
cost = tune()
rbf_sigma = tune()
Computational engine: kernlab
Model parameter tuning
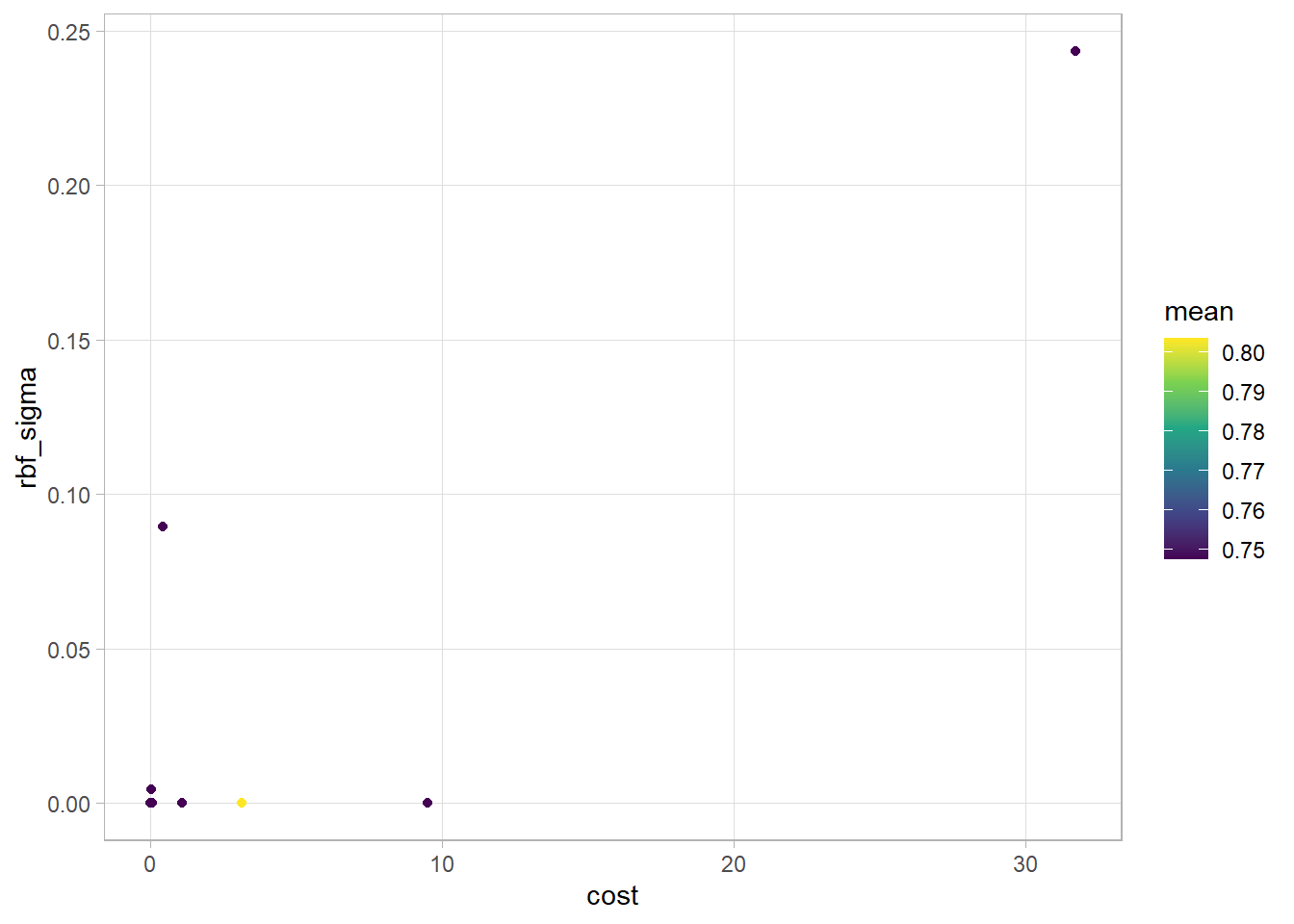
The model parameters cost and rbf_sigma will be tuned via a grid search of 10 values
The optimal tuning parameters for accuracy appears to be 3.154 for cost and 0 for rbf_sigma. We will use these parameters for our final model. We will fit our final model on the full training data, and assess the performance on the test data.
The model appears to be doing a decent job classifying the artist by the lyrics of the songs with an overall accuracy of 80.2%. Furthermore, the model appears to be doing a better job at classifying Beyonce lyrics than Taylor Swift’s
Let’s have a closer look at the songs that were misclassified from our model
@online{luu2020,
author = {Luu, Michael},
title = {Natural {Language} {Processing} {(NLP)} and Developing a
Machine Learning Classifier on {Beyonce} and {Taylor} {Swift} Lyrics
{\#TidyTuesday}},
date = {2020-10-02},
langid = {en}
}
For attribution, please cite this work as:
Luu, Michael. 2020. “Natural Language Processing (NLP) and
Developing a Machine Learning Classifier on Beyonce and Taylor Swift
Lyrics #TidyTuesday.” October 2, 2020.